run-length encoding
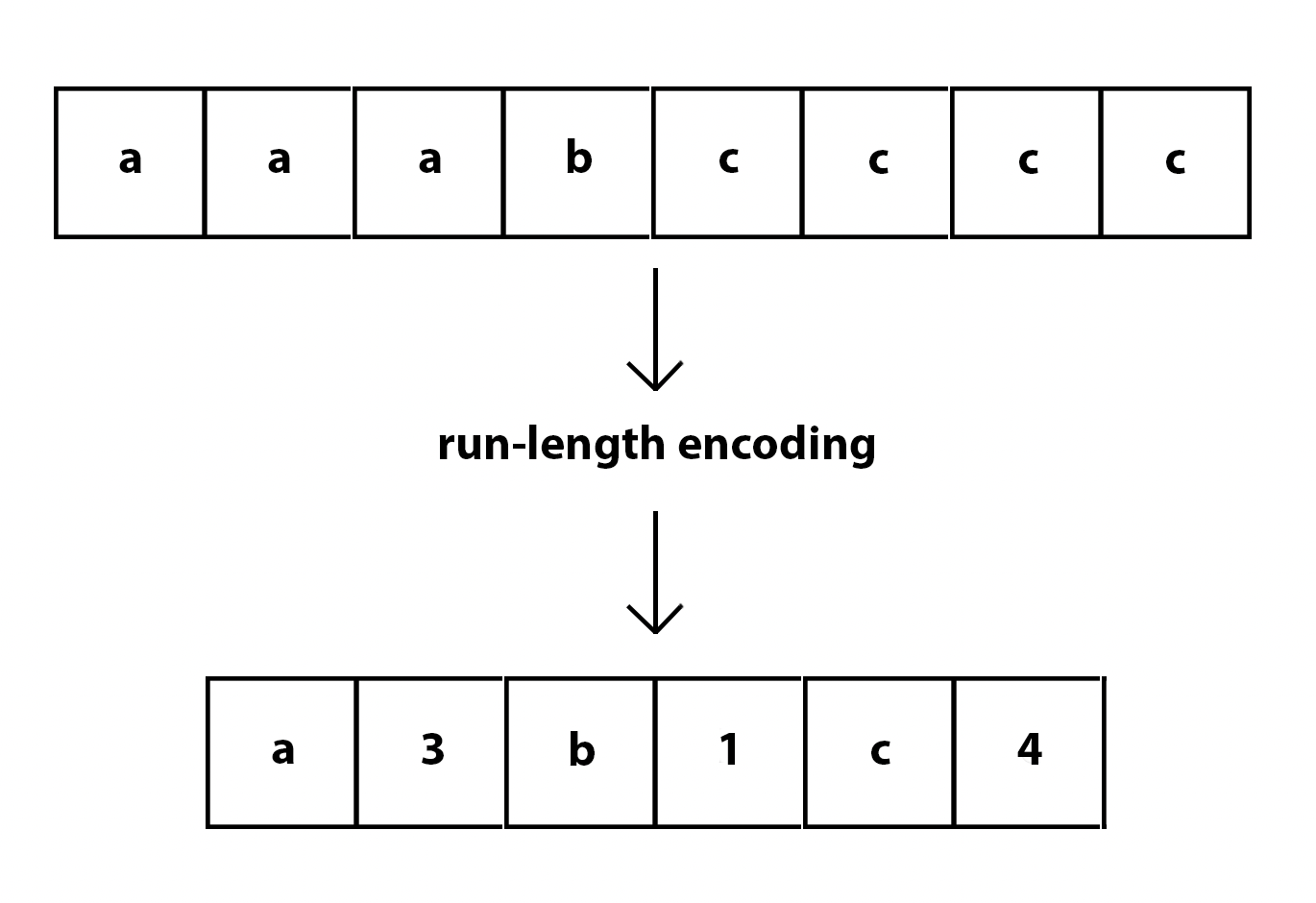
What is run-length encoding?
Run-length encoding (RLE) is a lossless compression method where sequences that display redundant data are stored as a single data value representing the repeated block and how many times it appears in the image. Later, during decompression, the image can be reconstructed exactly from this information.
This type of compression works best with simple images and animations that have a lot of redundant pixels. It's useful for black and white images in particular. For complex images and animations, if there aren't many redundant sections, RLE can make the file size bigger rather than smaller. Thus it's important to understand the content and whether this algorithm will help or hinder.
History of run-length encoding
This technique was first patented by Hitachi in 1983. It's less popular today because there are other more advanced options available, but you will still find it in use for color for fax machines, icons, line drawings and simple animations. You'll also find it in TIFF and PDF files. However, this compression was regularly used when transmitting analog television signals all the way back to 1967! (Way before Hitachi patented it!)
Run-length encoding and LZ77
LZ77 is an algorithm that compresses data in a similar way to RLE. It replaces repeated occurences of data with a reference to a single copy of that data that exists earlier in the uncompressed stream. If there's a match to a chunk of data, then LZ77 encodes a match that represents the distance between the two chunks of data and the length of each chunk. To find matches, LZ77 has to track a chunk of recent data, which can be of varying sizes. The bigger the chunk of recent data, the bigger a chunk it can search through for a match. Because it's viewing a chunk of data that can be of varying sizes to find matches, it's sometimes called sliding-window compression. Pairs can repeat multiple times, so it's like RLE, but a bit more complex.
The concept used to create RLE doesn't just appear in LZ77, but also in LZ78 and popular compression methods we still use today like GIF and DEFLATE. The DEFLATE algorithm appears in PNG and ZIP.
Drawbacks of run-length encoding
In addition to needing to be paired with simple and repetitive data, RLE has a few other drawbacks:
- The original data isn't instantly accessible, you must decode everything before you can access anything.
- You can't tell how large the decoded data will be, which could be a problem if you have limited space to decompress the file in. One workaround is to store the size of the data as metadata somewhere, or use this with a dynamic buffer and enough space to decompress the content in.
If you're interested in learning more about the history of video compression and the different algorithms that have appeared over time, check out The History of Video Compression Standards, From 1929 Until Now.